前言
最近参加一个小实践活动,本来想着最近西安的疫情,写一个疫情地图,但刚好我的一个高中同学问我买什么基金,本来我建议它全仓梭哈btc的,但他不喜欢这种高风险的东西,然后我让他买私募,但私募门槛对大部分大学生不是很友好,然后我让他梭哈股票,他又不想搞就单纯想买个基金,我对公募也不是很了解就有了这个小实践 其实疫情地图我也写好了,点这里就可以看http://154.222.29.49:8080/ 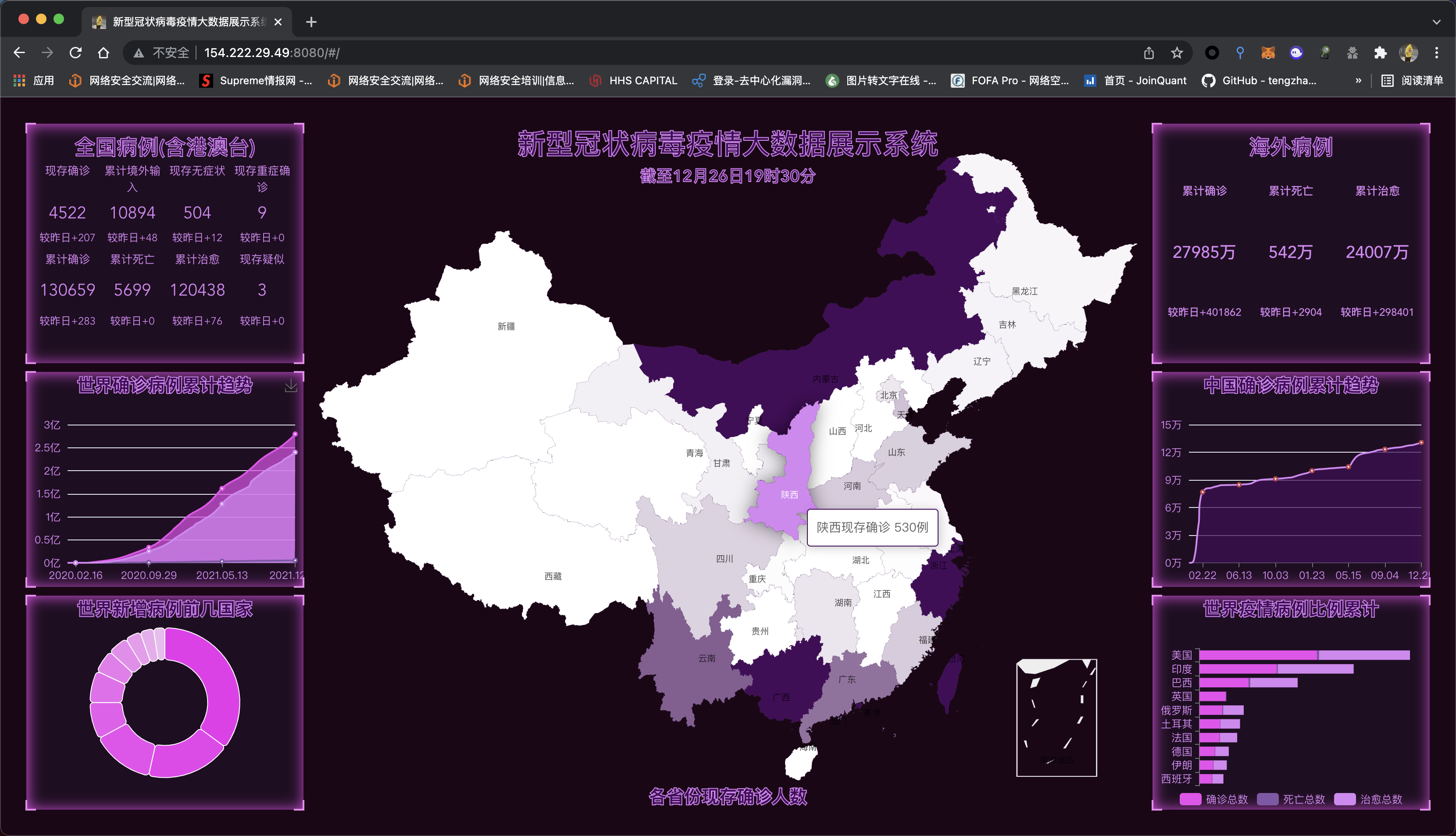
项目概述
项目地址
https://gitee.com/exp1ore/fund-crawler-and-data-analysis
使用方法
git clone https://gitee.com/exp1ore/fund-crawler-and-data-analysis.git
pip install -r requirement.txt
python main.py --help #查看帮助
成果保存在file目录下
运行截图
 运行截图
运行截图
To do
基金分类
股票基金
绝大部分资金都投在股票上面的基金,股票投资比例占基金资产的80%以上。
债券基金
绝大部分资金都投在债券上面的基金,债券投资比例为总资金的80%以上。
混合型基金
将部分资金投在股票上面而另一部分资金投在债券上的基金(投资比例可以变化调整).
货币基金
全部资产都投资在各类短期货币市场上的基金。短期货币工具包括国债、央行票据、商业票据、银行定期存单、政府短期债券、同业存款等。
QDII基金
QDII是Qualified Domestic Institutional Investor (合格的境内机构投资者)的首字缩写。它是在一国境内设立,经该国有关部门批准从事境外证券市场的股票、债券等有价证券业务的证券投资基金。与此相应地还有一类基金是QFII基金,QFII是指合格境外机构投资者,即外国投资者将资金转换为本国货币,投资于国内证券市场。
ETF基金
ETF指交易型开放式指数基金。ETF是一种在交易所上市交易的开放式证券投资基金产品,交易手续与股票完全相同。ETF管理的资产是一揽子股票组合,这一组合中的股票种类与某一特定指数,如上证50指数,包涵的成份股票相同,每只股票的数量与该指数的成份股构成比例一致,ETF交易价格取决于它拥有的一揽子股票的价值,即“单位基金资产净值”。
LOF基金
LOF,“Listed Open-Ended Fund”即上市开放式基金,它是我国对证券投资基金的一种本土化创新。LOF既可以通过基金销售机构进行基金份额申购或赎回,又可以通过证券账户在交易所进行基金份额申购或赎回,还能够在交易所像买卖股票一样进行基金份额交易。
FOF基金
FOF的英文全称为“Fund of Funds”,即“基金中基金”。公募FOF将80%以上的基金资产投资于经中国证监会依法核准或注册的公开募集的基金,这类产品的基本特点是将大部分资产投资于“一篮子”基金,而不是股票、债券等金融工具。
爬取思路
获取基金数据
选择爬取的对象是天天基金网 访问链接http://fund.eastmoney.com/trade/gp.html 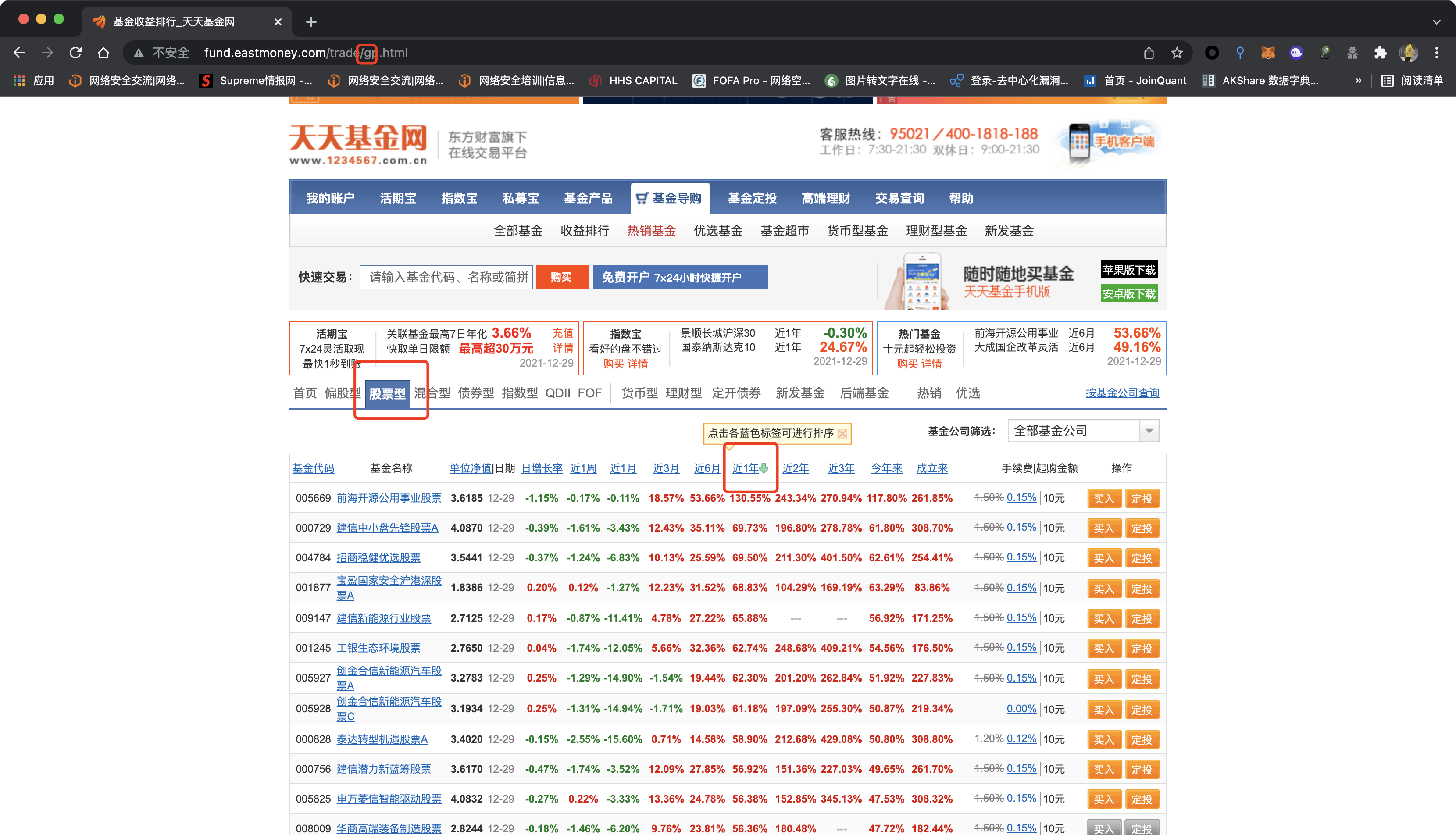 通过抓包发现接口,采集字段的时候获取每个基金所有的收益率情况
通过抓包发现接口,采集字段的时候获取每个基金所有的收益率情况 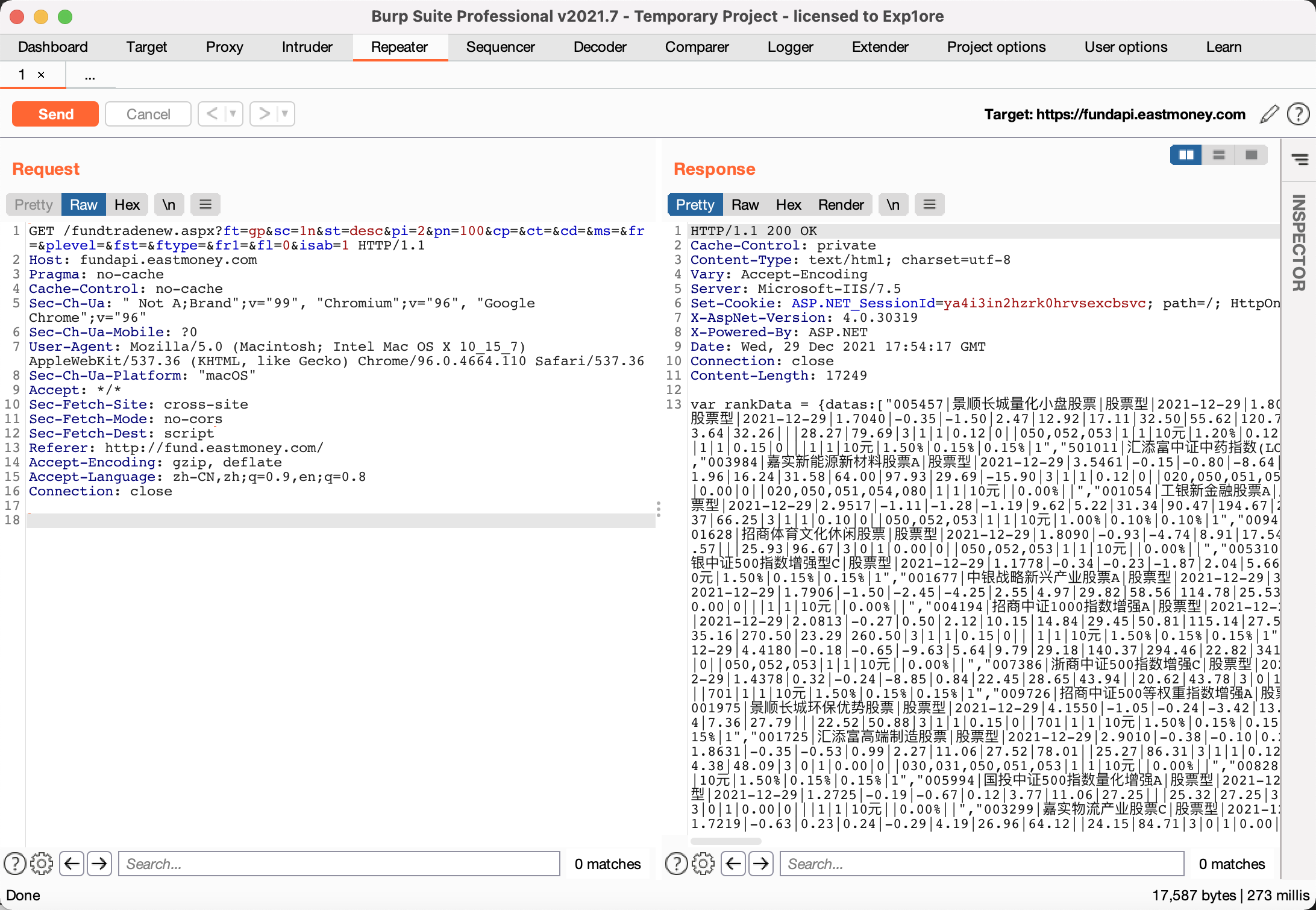
获取基金持仓数据
以这个为例前海开源公用事业股票(005669)基金净值_估值_行情走势—天天基金网 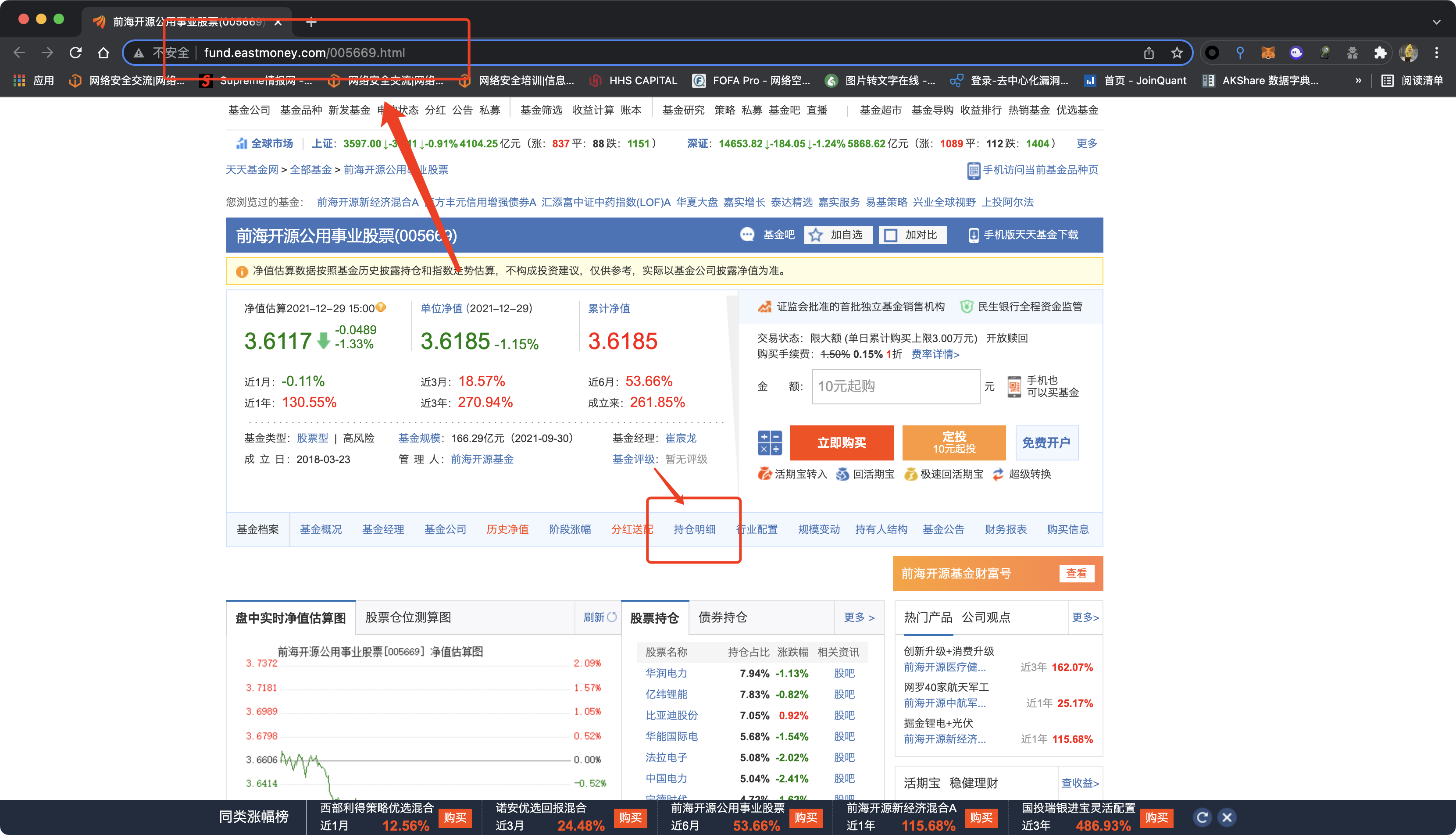 通过抓包获取接口,主要包括基金的成立时间、规模、基金经理以及每个季度的详细持仓情况
通过抓包获取接口,主要包括基金的成立时间、规模、基金经理以及每个季度的详细持仓情况 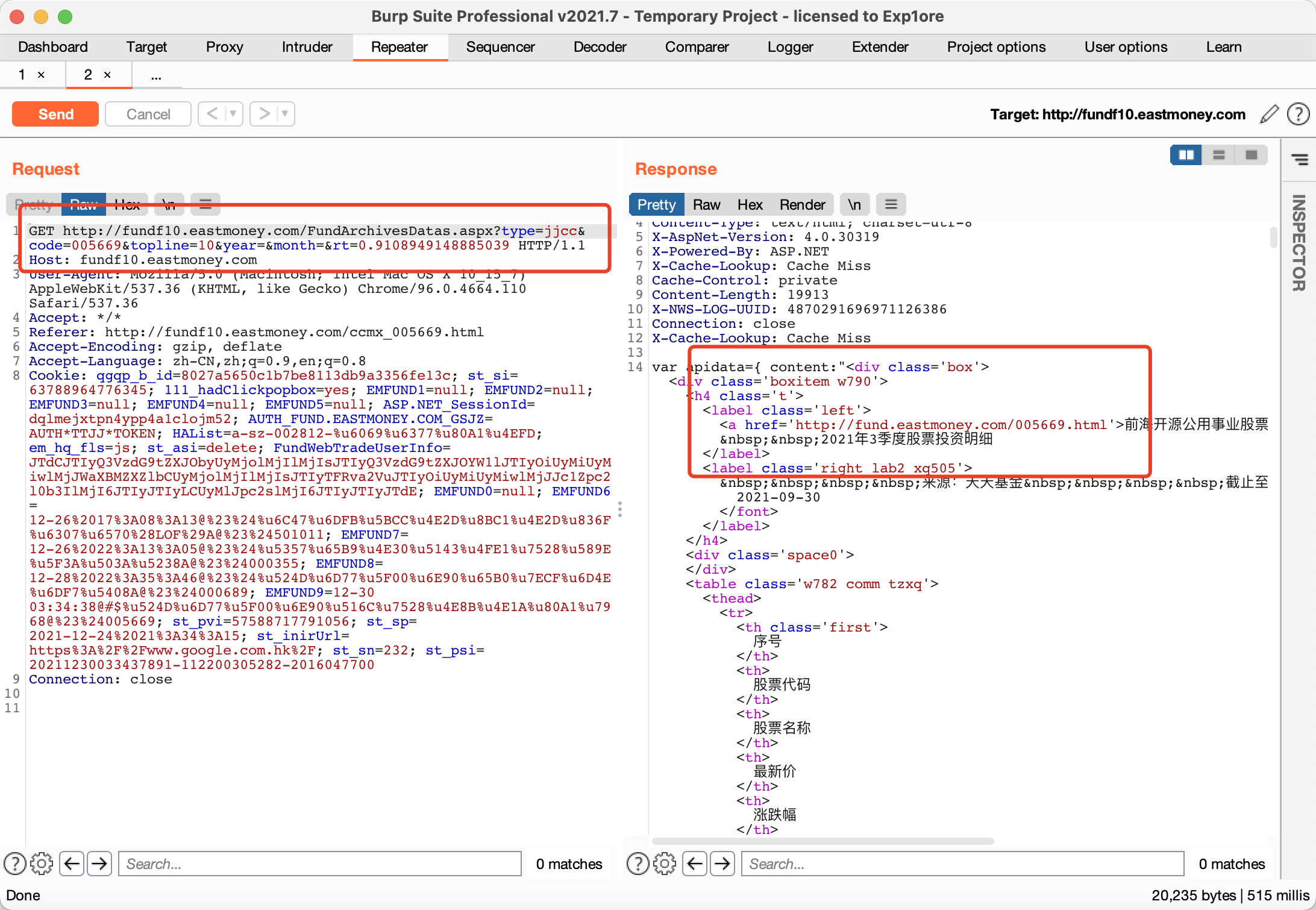
其他接口同理
对爬取的数据进行数据分析
基于这些方面进行数据分析 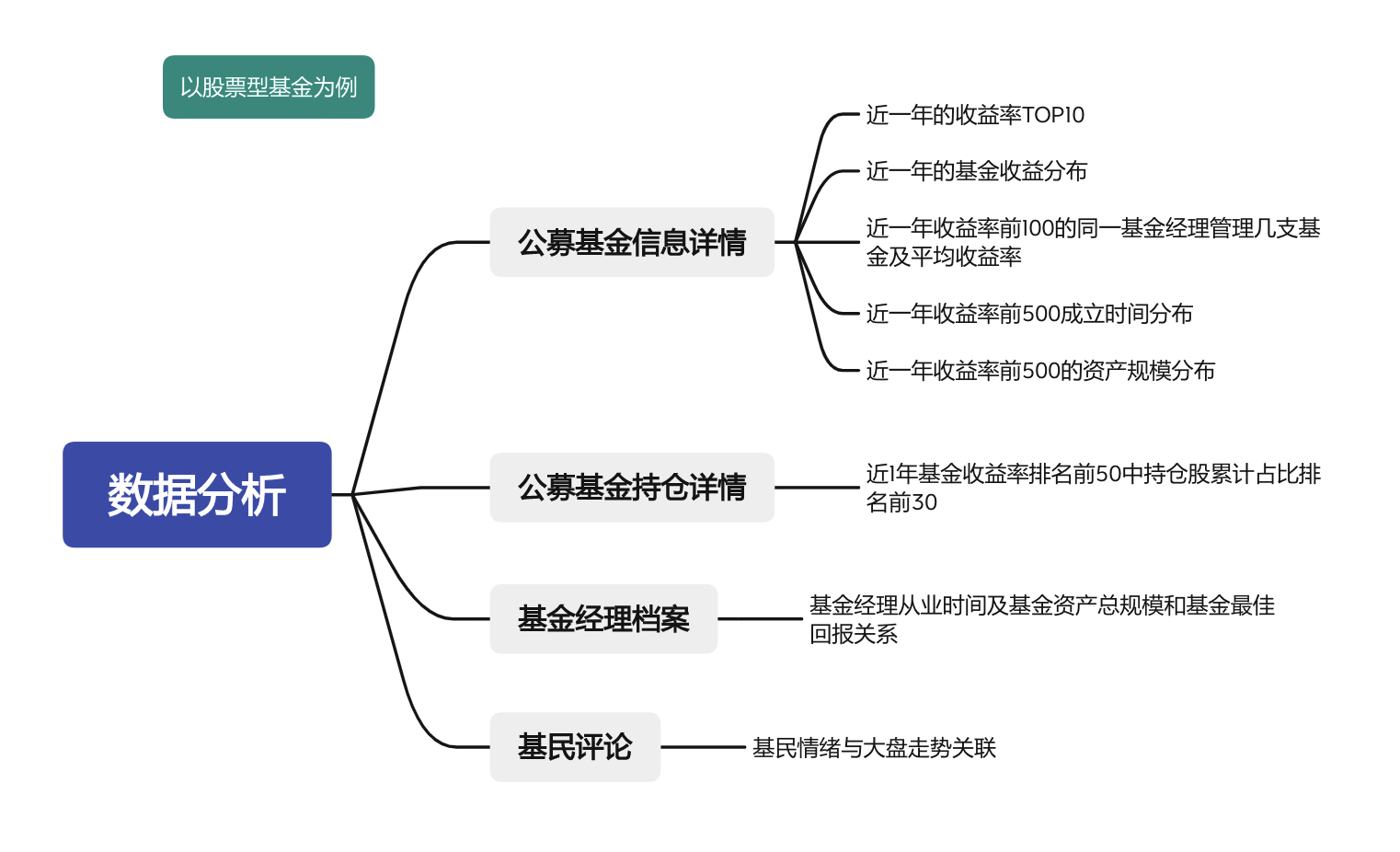
代码及数据分析(以股票型基金为例)
某基金的评论生成的词云图
 看这个词云图,就可以看到大部分人买基金运气都不太好,都希望快点回本,我也是,之前买了170w的中概互联513050,前几天又加了仓,现在持有不少,都来梭哈,强烈看好游戏霸主腾讯
看这个词云图,就可以看到大部分人买基金运气都不太好,都希望快点回本,我也是,之前买了170w的中概互联513050,前几天又加了仓,现在持有不少,都来梭哈,强烈看好游戏霸主腾讯
情感分析得到的情感指数与大盘走势关联(日内)
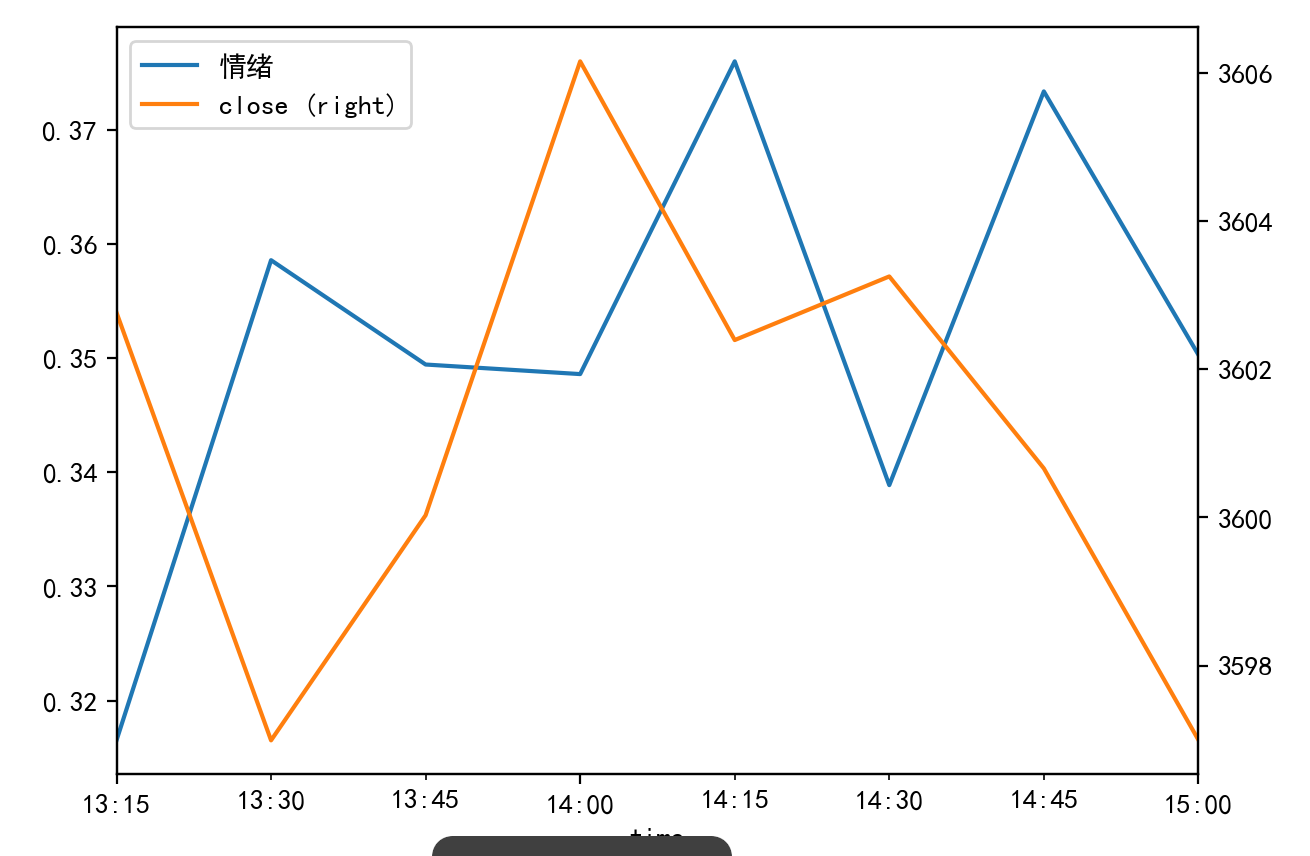 我爬了个跟大盘关联度高的基金,然后进行的情感分析,可以看出,散户都是在涨之后情绪才起来,喜欢追涨杀跌,容易被来回收割,所以我们要大胆抄底哈哈,buy the dip,don't fomo
我爬了个跟大盘关联度高的基金,然后进行的情感分析,可以看出,散户都是在涨之后情绪才起来,喜欢追涨杀跌,容易被来回收割,所以我们要大胆抄底哈哈,buy the dip,don't fomo
近一年的基金收益分布
1
| distribution = df_1["近1年"].groupby(pd.cut(df_1["近1年"], range(-15, 135, 10))).count()
|
1
2
3
4
5
6
7
8
9
10
| import matplotlib.pyplot as plt
from matplotlib import font_manager
font_path = 'SimHei.ttf'
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)
plt.rcParams["font.family"] = "SimHei"
plt.rcParams['font.sans-serif'] = prop.get_name()
|
1
2
| distribution.plot(kind="bar", figsize=(12,6), color="green")
plt.show()
|
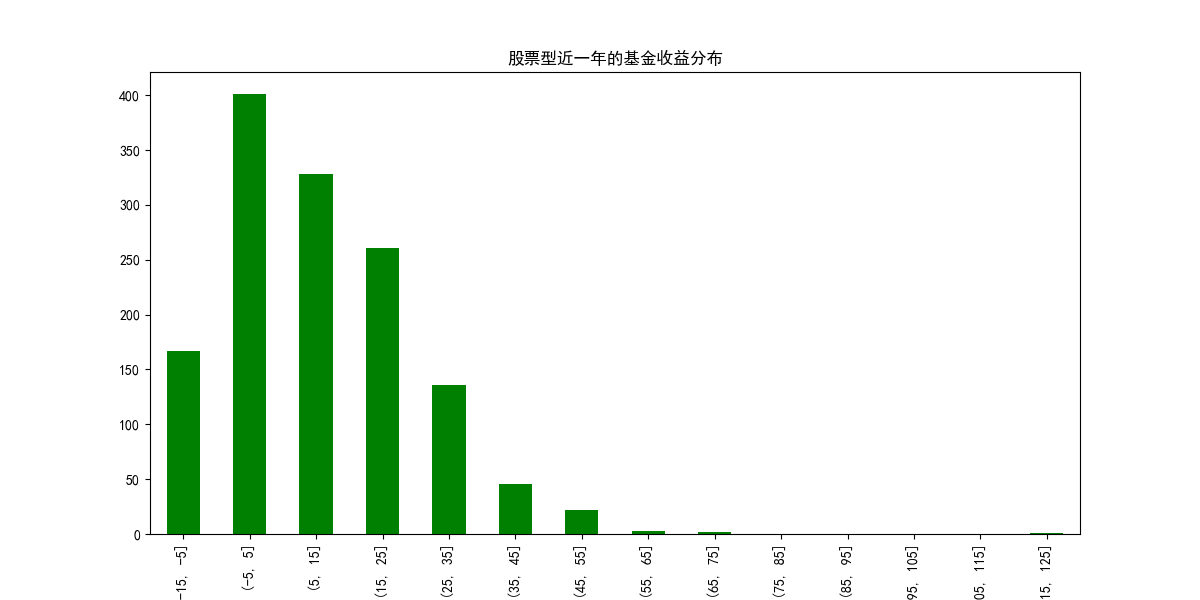 从中我们可以看出大部分基金收益集中在0-35%区间,5%以下有近550只,爬取的近一年收益有数据的有1400只,这么看差不多有40%的概率是不赚钱的,难受
从中我们可以看出大部分基金收益集中在0-35%区间,5%以下有近550只,爬取的近一年收益有数据的有1400只,这么看差不多有40%的概率是不赚钱的,难受
近一年收益率前十的基金
1
2
3
4
5
6
7
8
9
10
11
12
13
|
df_1.sort_values("近1年", ascending=False)[:10]
fig = plt.figure(figsize=(20,8))
plt.bar(df_1.sort_values("近1年", ascending=False)[:10]['基金名称'], df_1.sort_values("近1年", ascending=False)[:10]['近1年'])
plt.plot(df_1.sort_values("近1年", ascending=False)[:10]['基金名称'], df_1.sort_values("近1年", ascending=False)[:10]['近1年'],c="red")
plt.grid()
plt.show()
|
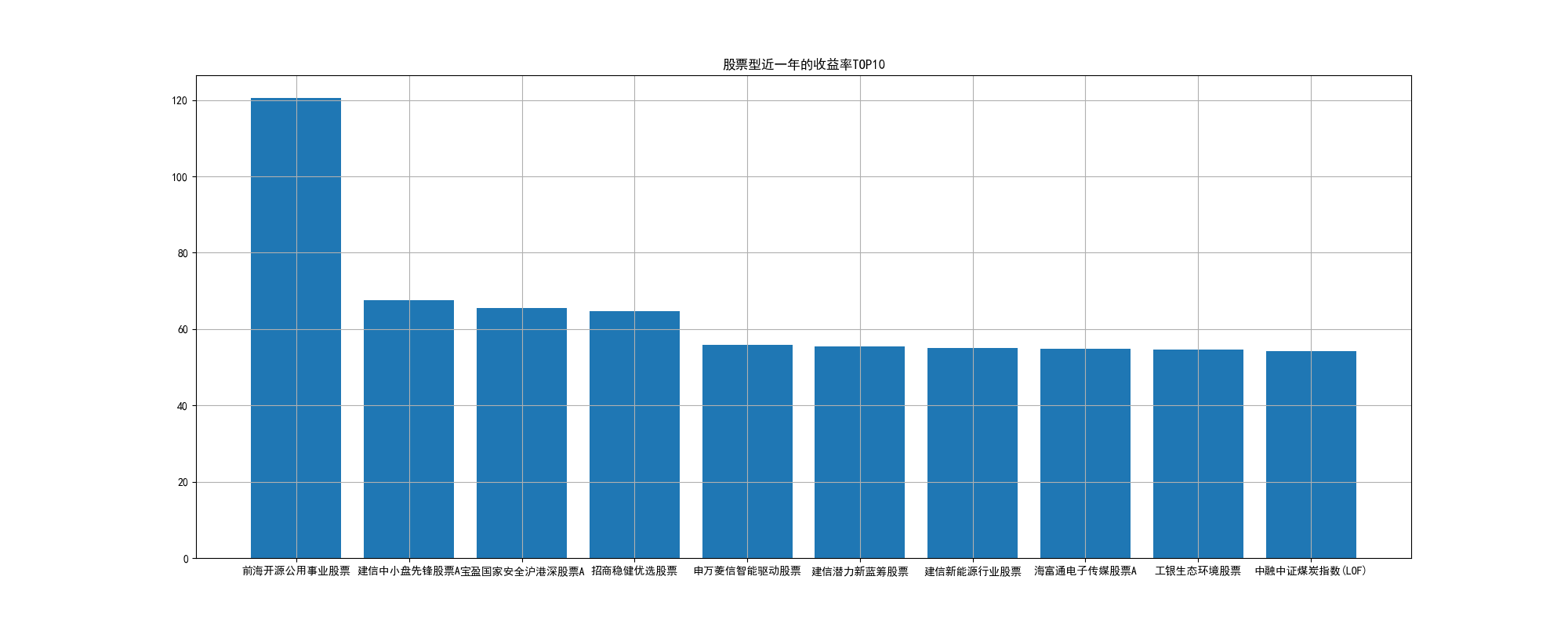 收益排名前十的基金,搞了上个季度的TOP10,这个排名轮动的还挺快的,所以可以看出大A的板块轮动挺重的,跟币圈都五五开了,哈哈哈
收益排名前十的基金,搞了上个季度的TOP10,这个排名轮动的还挺快的,所以可以看出大A的板块轮动挺重的,跟币圈都五五开了,哈哈哈
近一年收益率成立时间分布
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
order_yield = df_1.sort_values("近1年", ascending=False)
order_yield = order_yield.drop(order_yield[order_yield["成立日期"] == "--"].index)
o = order_yield[:100]["成立日期"].to_frame()
o['year'] = pd.to_datetime(o['成立日期']).dt.year
c = o["year"].groupby(pd.cut(o["year"], range(2009, 2022))).count()
fig = plt.figure(figsize=(20,8))
plt.scatter(x=c.index.astype(str), y=c.values,alpha=0.5,s=c.values*100,)
plt.show()
order_yield = df_1.sort_values("近1年")
order_yield = order_yield.drop(order_yield[order_yield["成立日期"] == "--"].index)
o = order_yield[-100:][["成立日期", "近1年"]]
o["成立日期"] = pd.to_datetime(o["成立日期"])
fig = plt.figure(figsize=(20,8))
plt.scatter(x=o["成立日期"], y=o["近1年"],alpha=0.5)
plt.xticks(pd.date_range(start='20100601',end='20211201', freq='320D'), rotation=30)
plt.show()
|
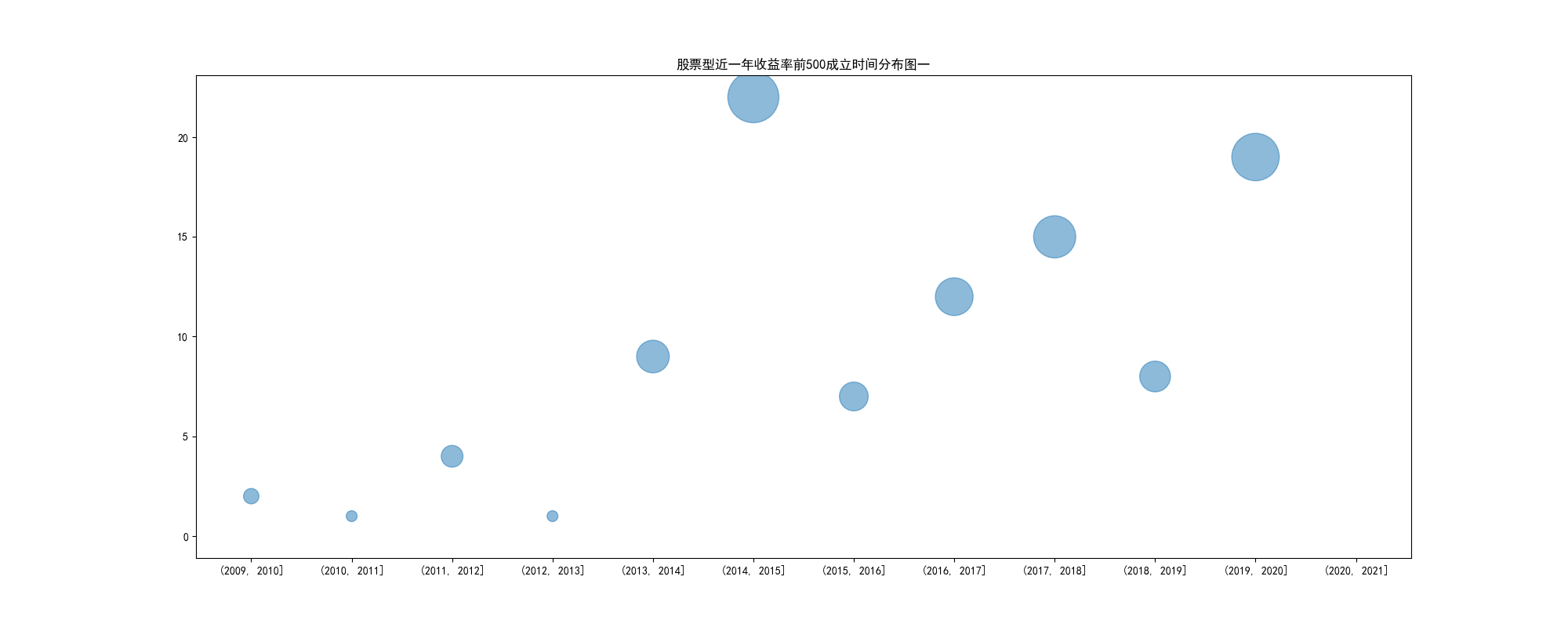
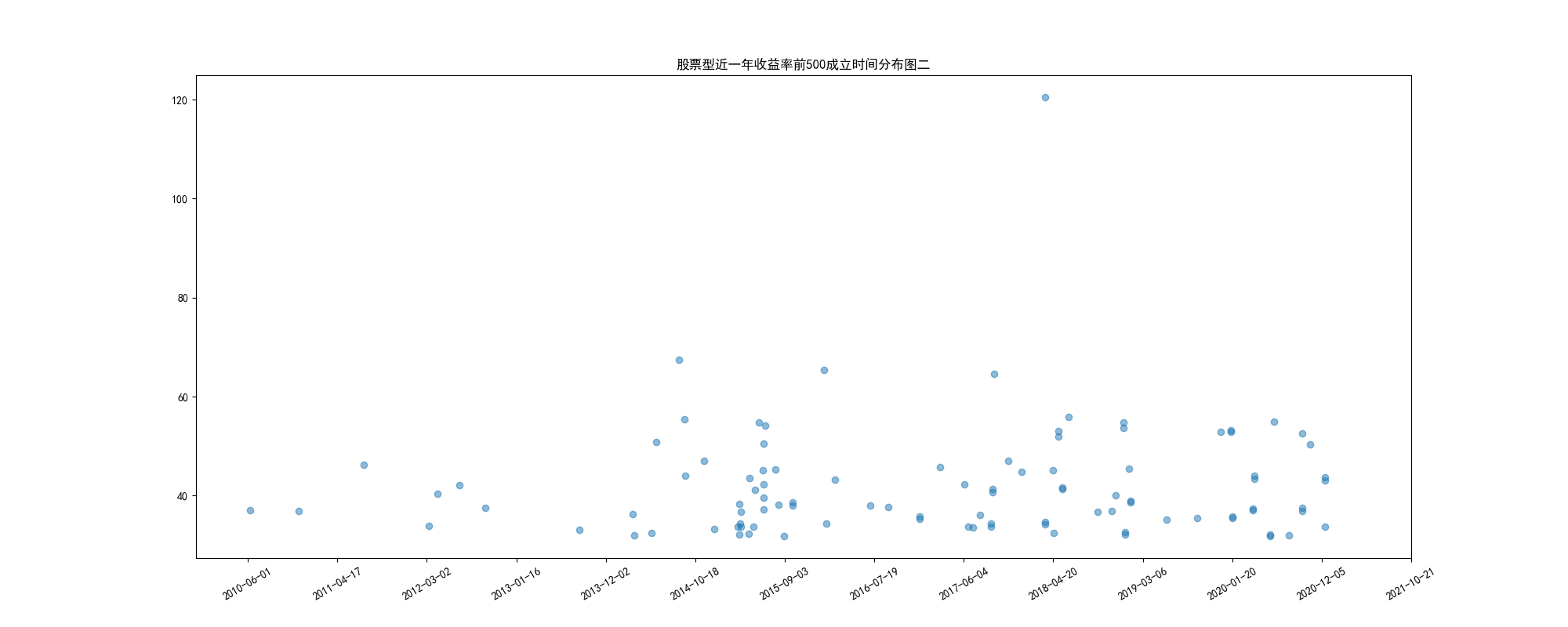 通过这两张图可以看出,赚钱的基金主要集中在14年10月到15年9月,17年7月到19年3月,20年1月到6月,这么看,看起来新基和老基都可以胡乱买,但新基金的缺点就是数据太少,可能没老基稳定,而且他们20年的基金都是在大放水之后的,还没有经过熊市,看基金还要看下牛熊转换的时候是什么样的,老基的经验可能会丰富一点
通过这两张图可以看出,赚钱的基金主要集中在14年10月到15年9月,17年7月到19年3月,20年1月到6月,这么看,看起来新基和老基都可以胡乱买,但新基金的缺点就是数据太少,可能没老基稳定,而且他们20年的基金都是在大放水之后的,还没有经过熊市,看基金还要看下牛熊转换的时候是什么样的,老基的经验可能会丰富一点
近一年收益前100中同一基金经理管理几支基金
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
order_yield = df_1.sort_values("近1年", ascending=False)
order_yield = order_yield.drop(order_yield[order_yield["基金经理"] == "--"].index)
order_yield = df_1.sort_values("近1年", ascending=False)
order_yield = order_yield.drop(order_yield[order_yield["基金经理"] == "--"].index)
size = order_yield[:100].groupby("基金经理").size()
revenue_df = order_yield[:100].groupby("基金经理").mean()
x_data = revenue_df.index
y_data = size
y_data2 = revenue_df["近1年"]
fig = plt.figure(figsize=(22, 10))
ax1 = fig.add_subplot(111)
ax1.bar(x_data, y_data)
ax1.set_ylim([0,6])
ax1.tick_params(axis='x', rotation=90)
ax2 = ax1.twinx()
ax2.plot(x_data, y_data2, c="red")
for x, y in zip(x_data, y_data2):
ax2.annotate(y, (x, y))
ax2.set_ylabel('近1年平均收益率')
ax1.set_ylabel('持有基金个数')
plt.show()
|
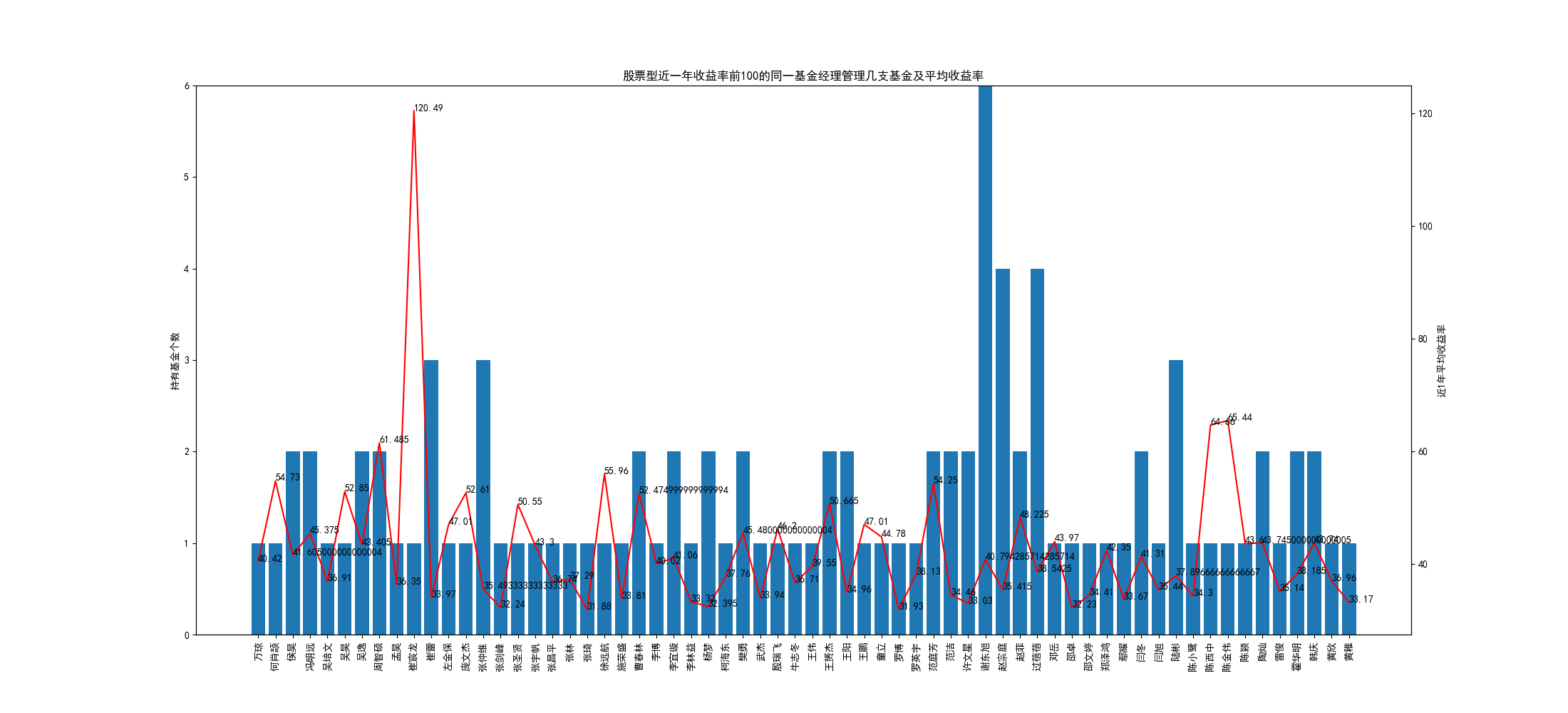 崔宸龙,崔雷,曹春林,范庭芳,谢东旭,陶灿等人看起来不错,我记得崔宸龙有只混合型基金今年表现也不错,这些人都可以多多关注
崔宸龙,崔雷,曹春林,范庭芳,谢东旭,陶灿等人看起来不错,我记得崔宸龙有只混合型基金今年表现也不错,这些人都可以多多关注
基金经理从业时间及基金资产总规模和基金最佳回报关系
1
2
3
4
5
6
7
8
9
10
11
12
| import matplotlib
from mpl_toolkits.mplot3d import Axes3D
plt.figure(figsize=(10,6),dpi=80)
ax=plt.axes(projection='3d')
ax.scatter(fund_manager_df['累计从业时间'].tolist(),fund_manager_df['现任基金资产总规模'].tolist(),fund_manager_df['现任基金最佳回报'].tolist())
ax.set_xlabel('累计从业时间')
ax.set_ylabel('现任基金资产总规模')
ax.set_zlabel('现任基金最佳回报')
plt.show()
|
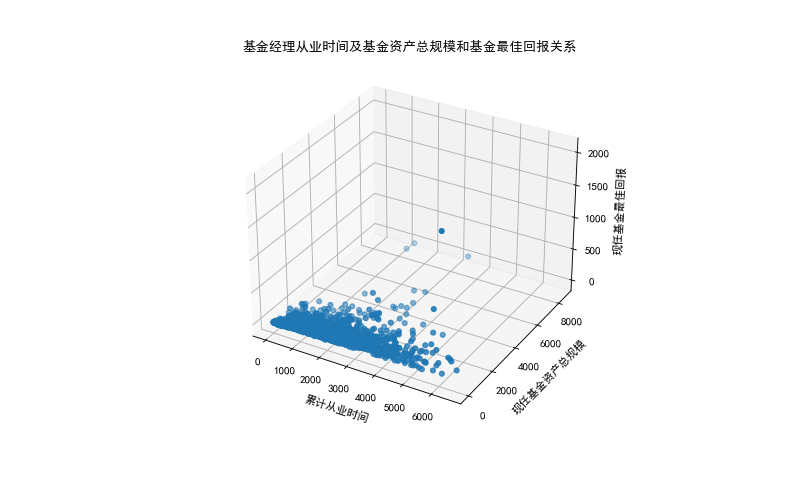 他们都说选基就是选基金经理,所以我分析了一下,看起来管理规模和从业天数在中间值,收益反而不错,也可以理解,规模太大的不敢动,从业太久的怕风险,等着养老...
他们都说选基就是选基金经理,所以我分析了一下,看起来管理规模和从业天数在中间值,收益反而不错,也可以理解,规模太大的不敢动,从业太久的怕风险,等着养老...
资产规模分布
1
2
3
4
5
| df_1['资产'] = df_1['资产规模'].str.extract(r"(\d+.\d+)亿元.*")
df_1['资产'] = pd.to_numeric(df_1['资产'], downcast='integer')
distribution = df_1["资产"].groupby(pd.cut(df_1["资产"], range(0, 125, 10))).count()
distribution.plot(kind="bar", figsize=(12,6), color="green")
plt.show()
|
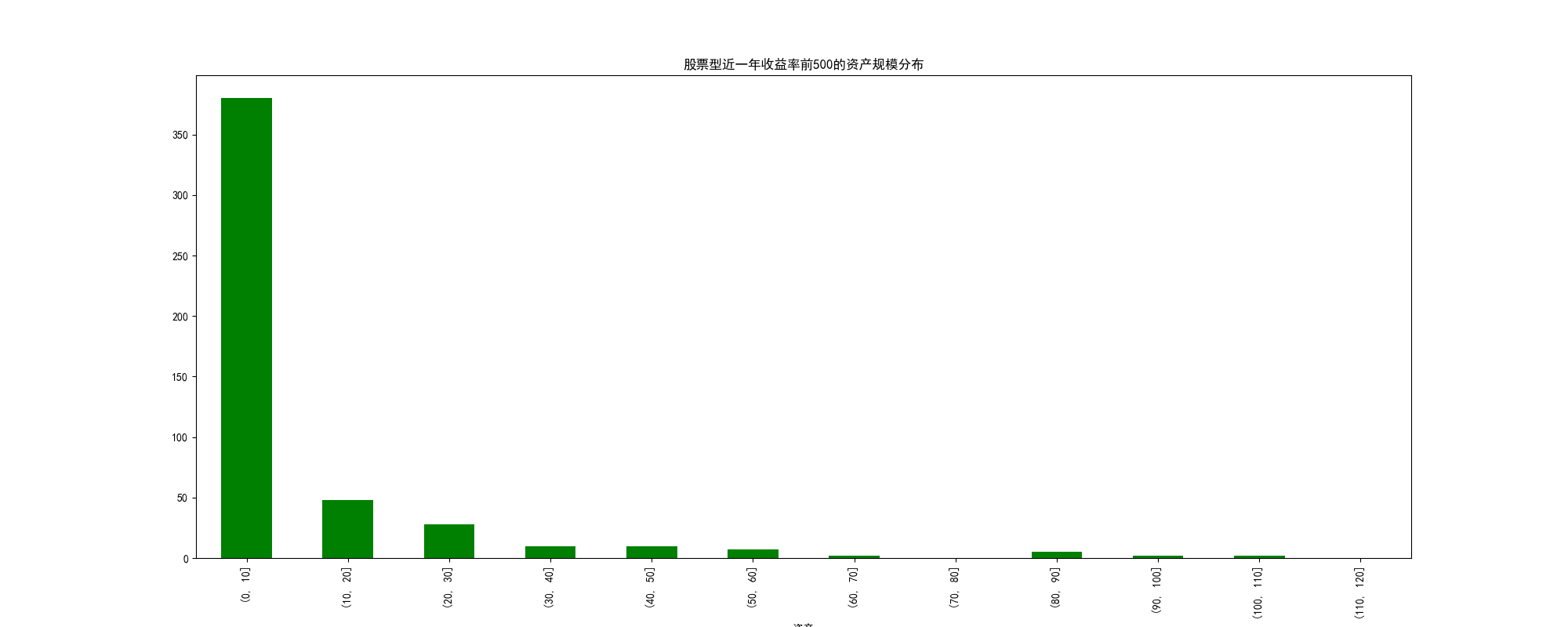 大部分规模都集中在10亿元以下,还好,可以理解
大部分规模都集中在10亿元以下,还好,可以理解
近1年收益率与资产规模关系
1
2
| df_1['资产'] = df_1['资产规模'].str.extract(r"(\d+.\d+)亿元.*")
df_1['资产'] = pd.to_numeric(df_1['资产'], downcast='integer')
|
1
2
3
4
5
6
7
8
| clear = df_1[['近1年', '资产']].dropna().sort_values("资产",ascending=False)
plt.scatter(clear['资产'], clear['近1年'],alpha=0.5,s=300)
plt.show()
|
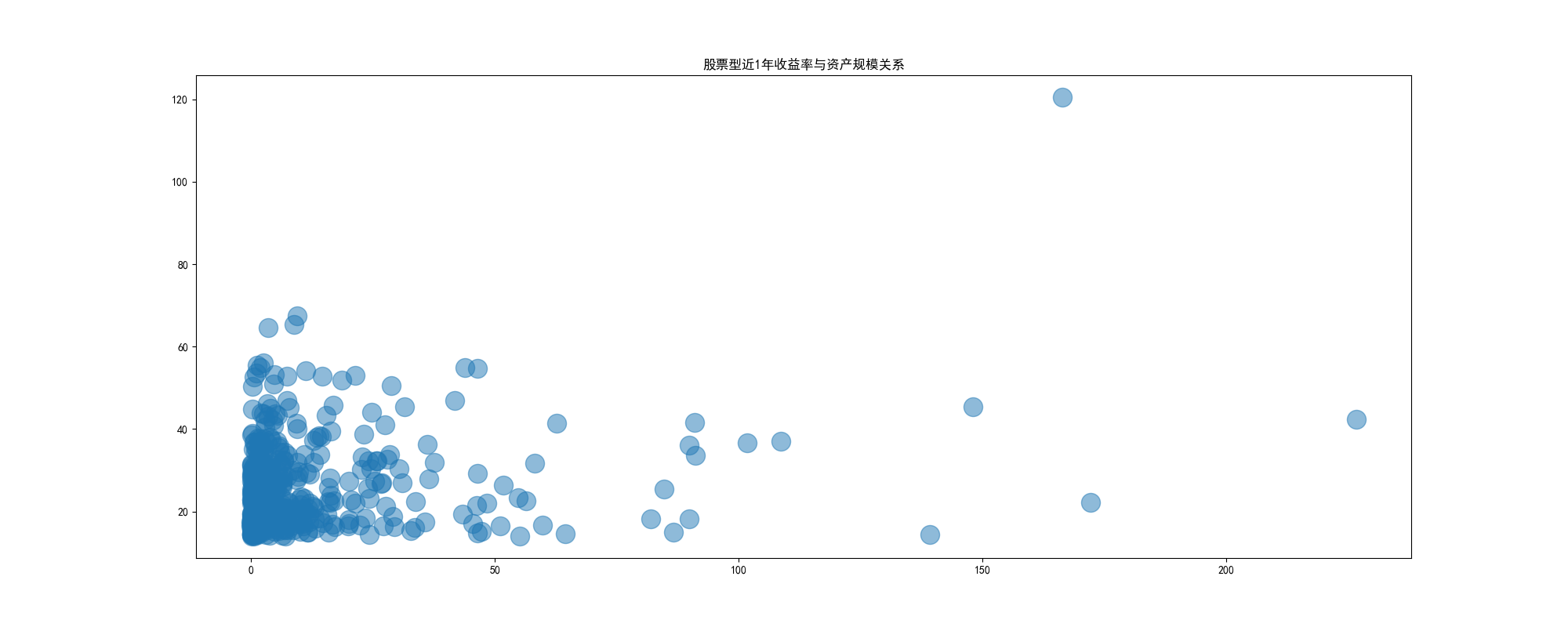 y轴是收益率,x轴是基金规模,懒得打代码了,从这可以看出,基金规模在50亿以下的收益和那些大规模的基金收益率五五开,因为大规模的不敢动,小规模的反而操作更灵活一点,这里有个政策,连续60日小于5kw的持仓人数少于200的会被清退,收益这里建议选5亿-50亿之间的,反正收益率都五五开,被清退的风险还小点,哈哈
y轴是收益率,x轴是基金规模,懒得打代码了,从这可以看出,基金规模在50亿以下的收益和那些大规模的基金收益率五五开,因为大规模的不敢动,小规模的反而操作更灵活一点,这里有个政策,连续60日小于5kw的持仓人数少于200的会被清退,收益这里建议选5亿-50亿之间的,反正收益率都五五开,被清退的风险还小点,哈哈
近1年基金收益率排名前50中 持仓股累计占比排名前30
1
2
| first_50 = df_1.sort_values("近1年", ascending=False)[:50]
concat = pd.merge(first_50, df_2, on="基金代码")[["持仓股票名称", "持仓股票占比"]]
|
1
2
| concat["持仓股票占比"] = concat["持仓股票占比"].str.extract(r"(.*)%").astype(float)
|
1
| concat.groupby("持仓股票名称").sum().sort_values("持仓股票占比", ascending=False)[:20]
|
|
|
持仓股票占比
|
|
持仓股票名称
|
|
|
宁德时代
|
178.86
|
|
赣锋锂业
|
78.43
|
|
亿纬锂能
|
74.10
|
|
恩捷股份
|
68.46
|
|
天齐锂业
|
64.88
|
|
比亚迪
|
55.45
|
|
华友钴业
|
54.39
|
|
隆基股份
|
50.97
|
|
天赐材料
|
49.95
|
|
诺德股份
|
45.63
|
|
阳光电源
|
39.29
|
|
璞泰来
|
37.37
|
|
杉杉股份
|
37.01
|
|
通威股份
|
35.04
|
|
兖矿能源
|
34.04
|
|
先导智能
|
33.93
|
|
长江电力
|
30.09
|
|
紫光国微
|
23.08
|
|
新宙邦
|
23.04
|
|
汇川技术
|
19.94
|
1
2
3
4
5
6
7
8
9
10
11
12
| first_50 = df_1.sort_values("近1年", ascending=False)[:50]
concat = pd.merge(first_50, df_2, on="基金代码")[["持仓股票名称", "持仓股票持股市值"]]
concat["持仓股票持股市值"] = concat["持仓股票持股市值"]/concat["持仓股票持股市值"].sum()
res = concat.groupby("持仓股票名称").sum().sort_values("持仓股票持股市值", ascending=False)[:30]
fig = plt.figure(figsize=(18,12))
plt.pie(res["持仓股票持股市值"],
labels=res.index,
autopct='%.2f%%',
)
plt.show()
|
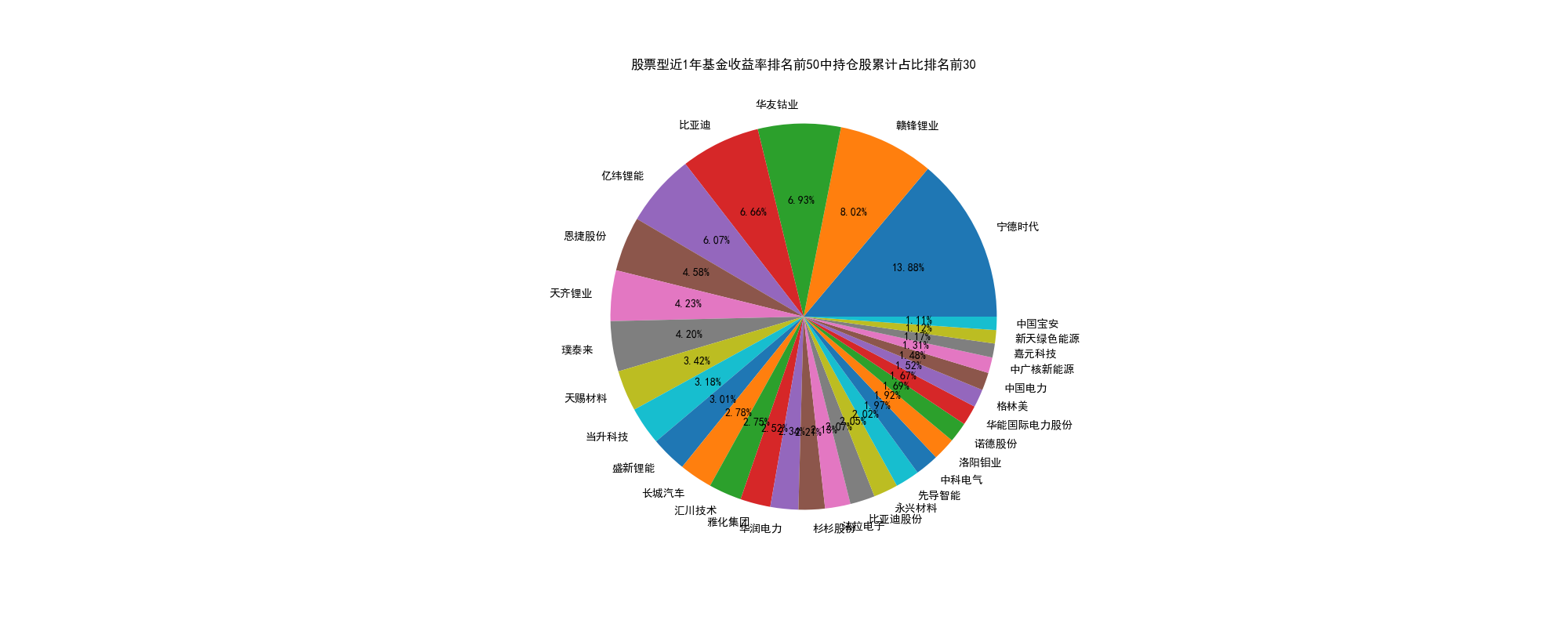 股票型近1年基金收益率排名前50中持仓股累计占比排名前30_Q3
股票型近1年基金收益率排名前50中持仓股累计占比排名前30_Q3
本来是用占比算的,但突然发现不对经,然后这里我用的是基金持仓市值/总市值来算的,我还爬了Q2季度的图,如下 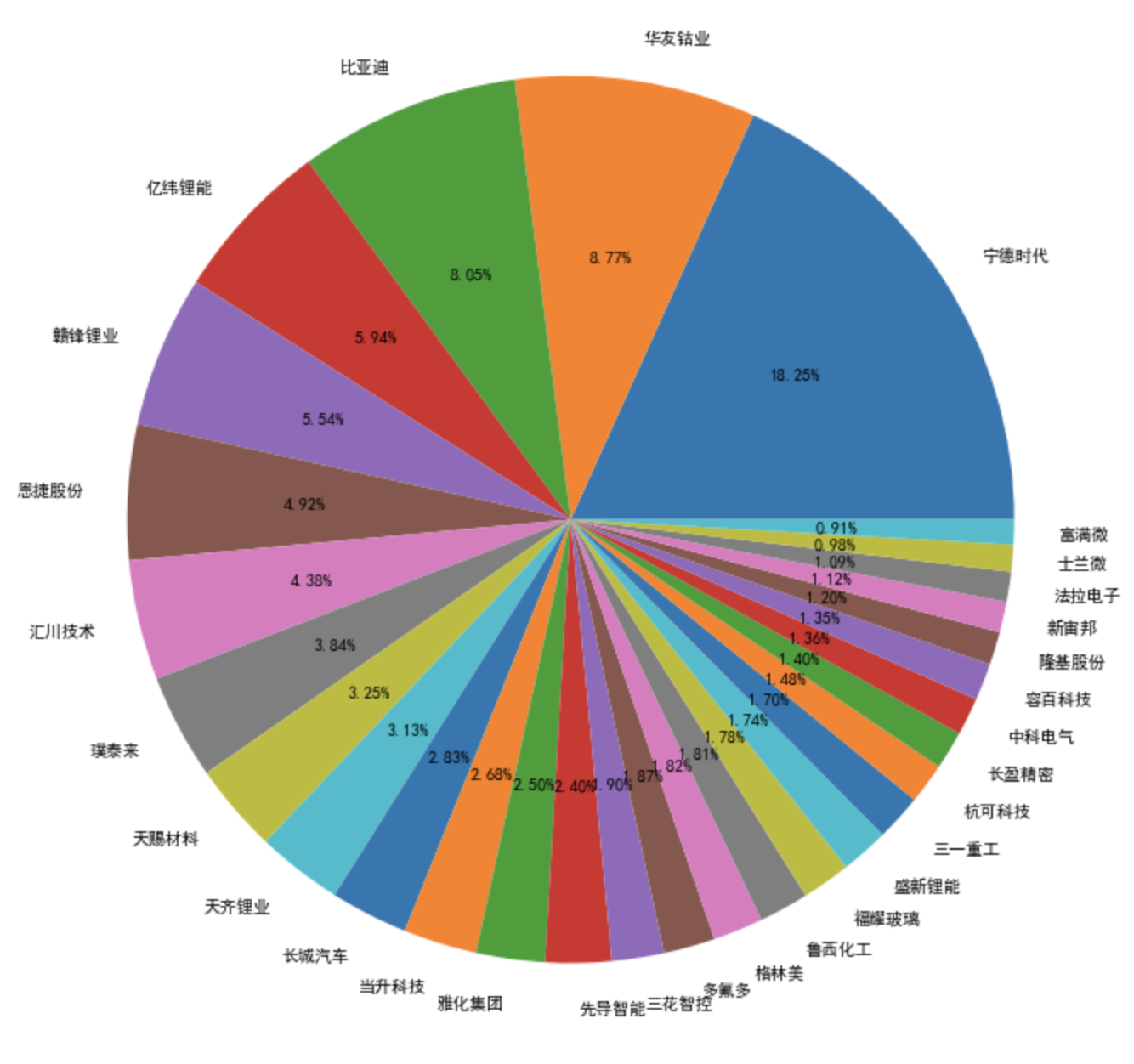 从中可以发现,新能源,光伏等股票的持仓在减少,也可以看出,板块轮动严重,已经不是以前吃药喝酒的时代了,所以我们应该布局低市值的股票
从中可以发现,新能源,光伏等股票的持仓在减少,也可以看出,板块轮动严重,已经不是以前吃药喝酒的时代了,所以我们应该布局低市值的股票
用数据解释该不该定投
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import akshare as ak
import pandas as pd
import datetime
hs300_df = ak.stock_zh_index_daily(symbol="sh000300")[['date','close']]
hs300_df = hs300_df[hs300_df['date']>datetime.date(2015,6,1)].set_index('date')
fees = 0.001
hs300_df['每期定投金额'] = 100
hs300_df['累计定投金额'] = hs300_df['每期定投金额'].cumsum()
hs300_df['每期定投数量'] = hs300_df['每期定投金额']/hs300_df['close']*(1-fees)
hs300_df['累计持有数量'] = hs300_df['每期定投数量'].cumsum()
hs300_df['累计持仓净值'] = hs300_df['累计持有数量']*hs300_df['close']
hs300_df[['累计定投金额','累计持仓净值']].plot(figsize=(16,8),grid=True,title='定投的资金曲线图')
|
<AxesSubplot:title={'center':'定投的资金曲线图'}, xlabel='date'>
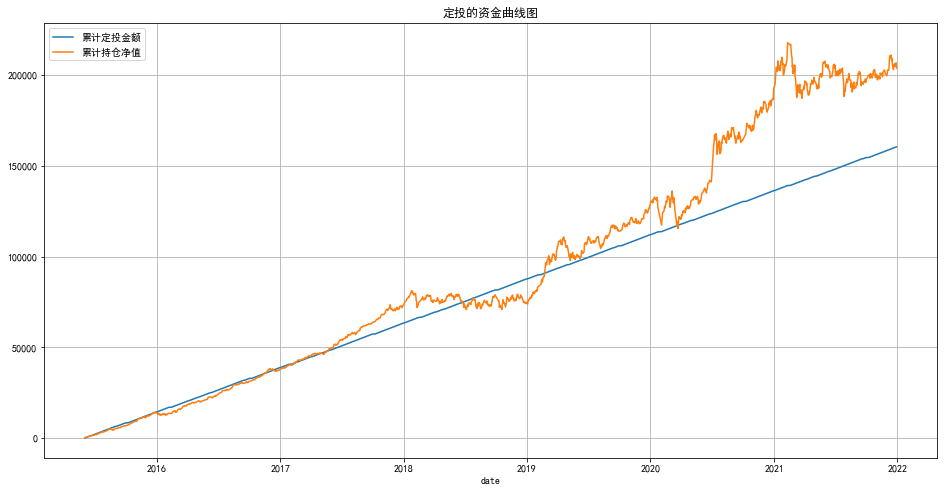 定投才是yyds,后面会分析一下用月定投好还是周定投好
定投才是yyds,后面会分析一下用月定投好还是周定投好
结论
基于上述数据分析,得出我们可以购买基金规模在20%到80%分位的基金(5-50亿) 基金经理可以关注崔宸龙,崔雷,曹春林,范庭芳,谢东旭,陶灿等人 可以关注那些从业天数,管理规模都不大不小,刚刚好的人 通过持仓可以看出板块轮动频繁,光伏从Q1的40%到现在的10+%,新能源的持仓也在减少,说明轮动频繁,所以股票建议选择低位的股票,闭眼梭哈
然后通过这个持仓的结论,想到了一个基于选持仓的Alpha因子选基的策略,所以可以将基金收益分为在不同风格上的配置收益加上选股收益。具体来说可以用以下公式表示:(R代表收益,ωi代表单个风格权重,Ri代表单个风格收益)
R = ω1R1 + ω2R2 + ω3R3 + ... + ωnRn
计算方法 用净值与各风格收益回归得到α,风格收益用巨潮大盘成长、大盘价值、中盘成长、中盘价值、小盘成长、小盘价值指数收益率代表 根据前一年风格指数每日收益和基金净值每日收益回归计算每种风格权重,然后用基金前一年累积收益率减去各风格累积收益率*权重得到alpha 在每个换仓日,计算上一期的收益,得到累计收益率
基于结论的选基策略 根据1月,7月的财报筛选基金规模在20%到80%分位的基金 在筛选出来的基金中 用上面的选持仓股Alpha因子选取TOP10基金
基于选持仓股Alpha因子基金规模等选取基金
后续会针对量化选基策略单独开一篇笔记
通过回测2015-2021年数据,得到收益率为300%+,这里y轴单位错了,但不影响数据,唯一缺点就是回撤幅度偏大,后续还需改进 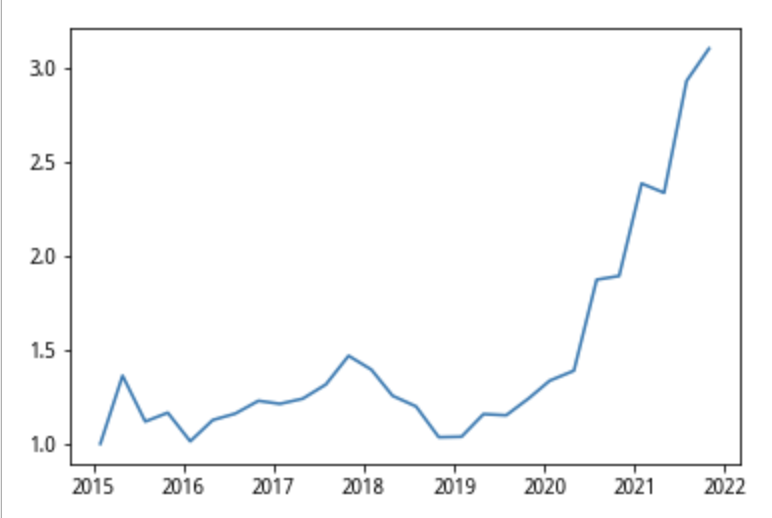 通过上述结论,选取了这段时间基于本策略应持有的基金如下
通过上述结论,选取了这段时间基于本策略应持有的基金如下 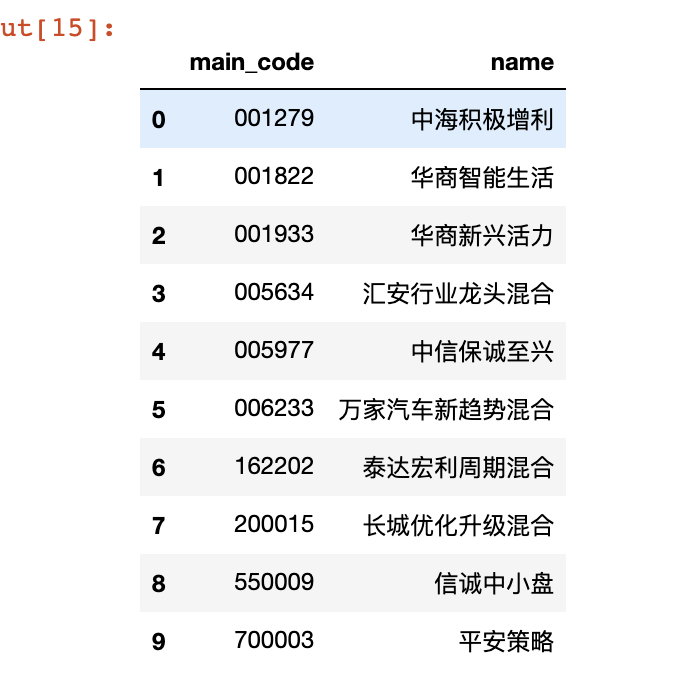
本文不构成投资建议。本文所有观点,仅代表个人立场以及个人操作,不具有任何指导作用,据此操作,风险自负